너비 우선 탐색과 깊이 우선 탐색
도입
너비 우선 탐색(BFS; Breadth First Search)과 깊이 우선 탐색(DFS; Depth First Search)은 어떤 대상을 처리할 때, 대상을 여러 개로 분할하여 처리하기 위해 반복 과정을 도입할 때 사용한다.
단순히 분할 가능한 대상을 처리할 때는 특별한 반복 과정 전략은 필요하지 않다. 일반적으로는 분할된 각 부분이 서로 특별한 관계성을 가질 때 사용한다. 대표적으로 이산수학의 그래프 이론에서의 그래프가 주로 BFS와 DFS의 적용 대상이다.
그래프에서의 각 부분이라고 할 수 있는 정점은 다른 정점들과 연결됨, 혹은 연결되지 않음이라는 관계성을 가지고 있다. 이 관계성을 해치지 않고 그래프 전체에 어떤 처리를 적용해야 하는, 이를테면 그래프 상에서의 경로 탐색과 같은 경우 BFS와 DFS를 사용하여 처리할 수 있다.
너비 우선 탐색과 깊이 우선 탐색
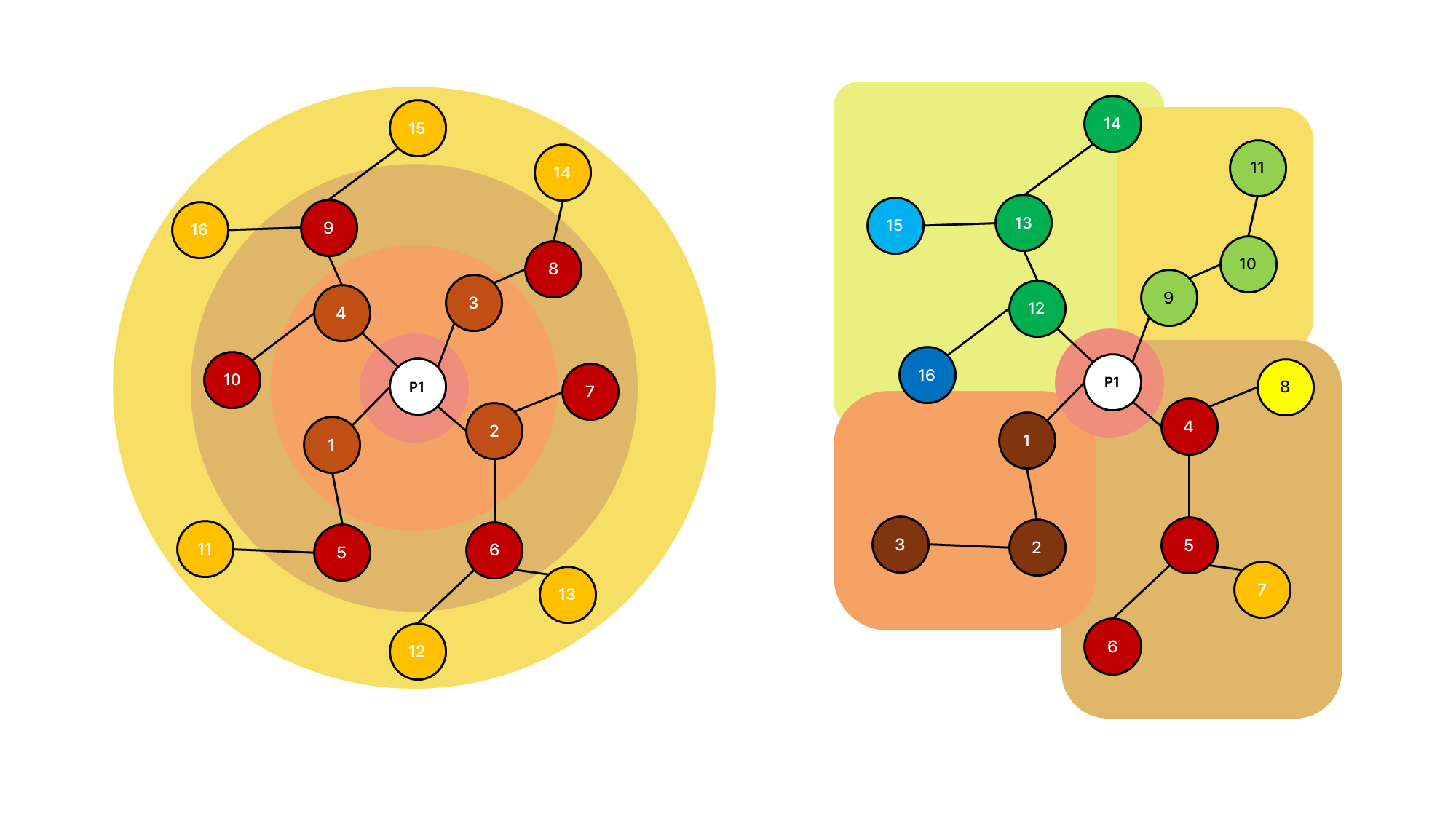
그림: $P_1$에서 탐색을 시작할 때, BFS(좌)와 DFS(우)
BFS와 DFS는 유사하지만, 그래프 상에서 정점을 처리하는 순서에 따라 구분된다.
BFS는 탐색을 시작하는 시작 정점으로부터 가까운 정점에서 먼 정점 방향으로 반복을 진행한다. 반면에 DFS는 시작 정점에서 다음 정점으로 진행 방향을 설정한 후에는, 진행 방향을 변경하지 않고 도달할 수 있는 가장 먼 정점까지 반복을 진행한다.
특히 트리에서 BFS는 반복이 진행됨에 따라 최대한 넓게 퍼져나가는 듯하게, DFS는 최대한 깊이 퍼져나가는 듯하게 보이므로 각각 너비 우선 탐색, 깊이 우선 탐색이라는 이름이 붙었다.
너비 우선 탐색의 구현
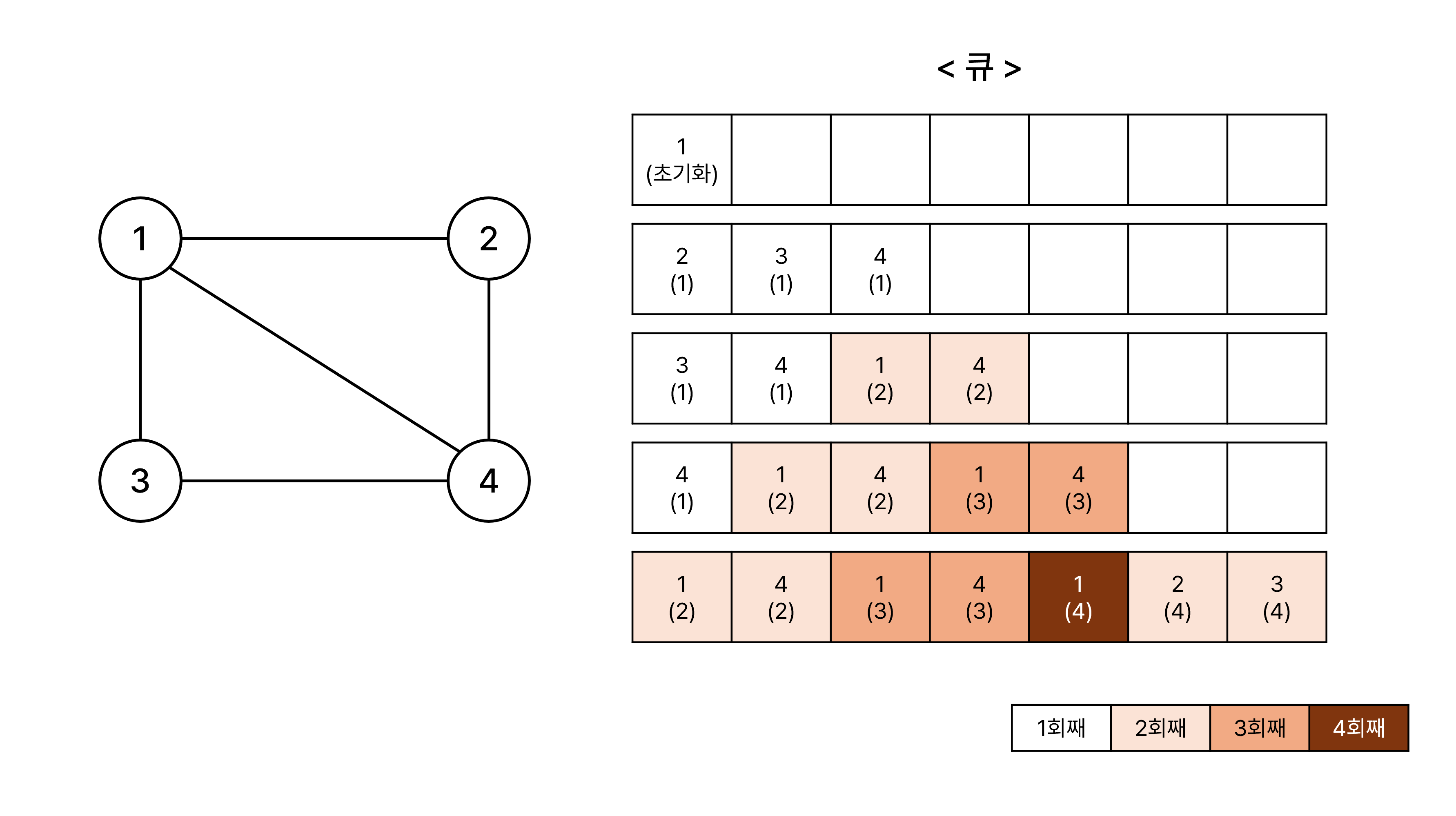
너비 우선 탐색은 일반적으로 큐를 사용하여 구현한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from collections import deque
INIT_NODE: int
# connections[n]: n번 정점과 연결된 정점들의 목록
# Key: int, 각 정점의 번호
# Value: list[int], 해당 정점에 연결된 다른 정점 번호들
connections: dict[int, list[int]]
q = []
q.append(INIT_NODE)
while q:
# 1
now = q.popleft()
for _next in connections[now]:
q.append(_next)
이해를 위해 핵심만 간략하게 표현: 이 코드는 이전에 방문한 정점을 다시 방문하게 되어 반복 과정이 종료되지 않는다.
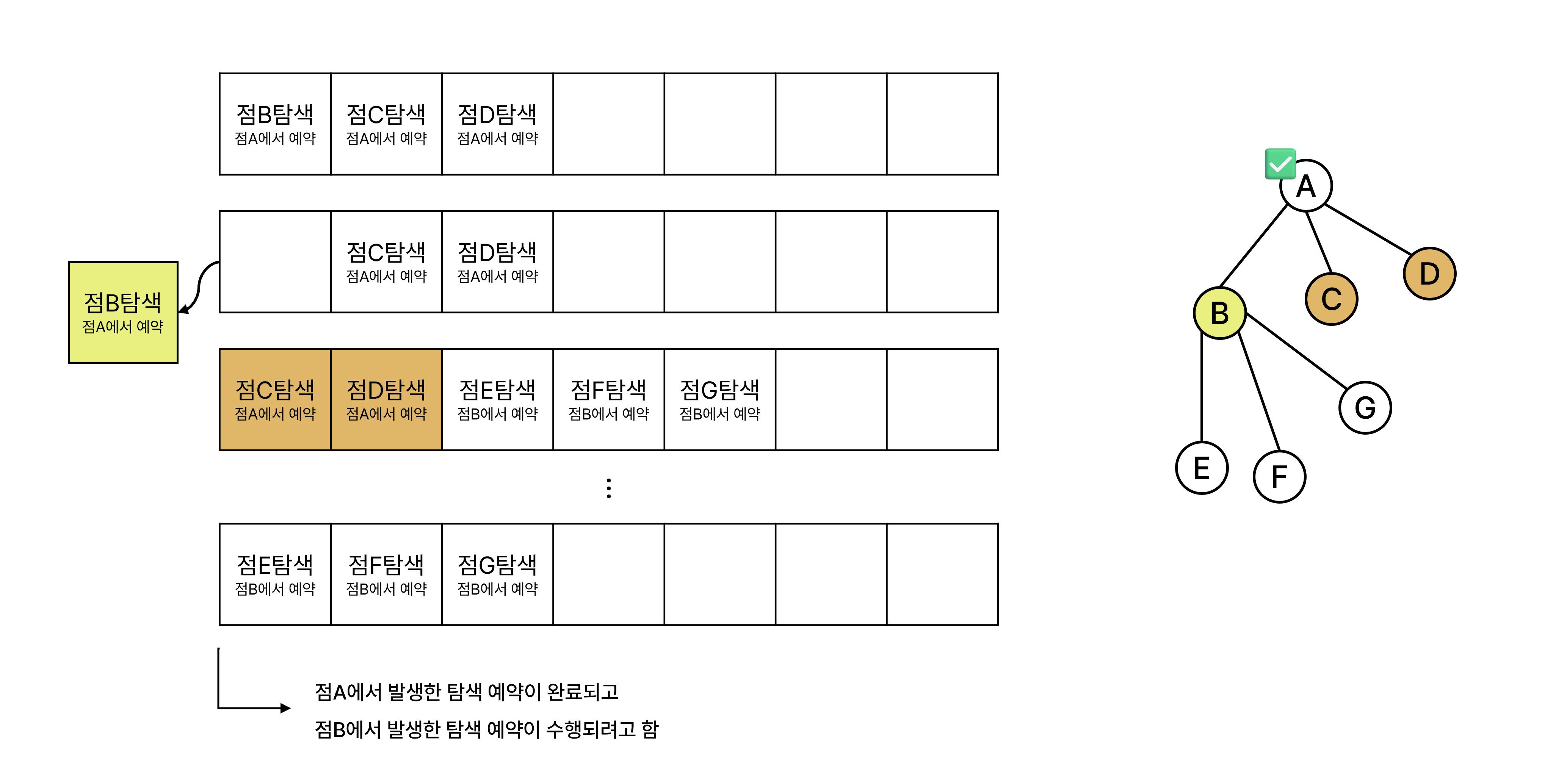
현재 처리하는 정점과 연결된 정점들을 큐에 삽입하고 이후에 반복 과정 중에 큐에서 값을 인출한다.(# 1) 큐는 선입선출 원리에 따라 먼저 삽입된 정점, 시작점에서 가까운 정점을 반환한다. 최초에는 시작점과 연결된 정점들이 큐에 삽입되고, 반복 과정이 진척됨에 따라 점차 그로부터 멀어지는 정점들이 삽입된다.
깊이 우선 탐색의 구현
깊이 우선 탐색은 재귀 함수, 혹은 반복문을 사용하여 구현한다. 일반적으로 재귀 함수를 사용한다.
1
2
3
4
5
6
7
8
9
INIT_NODE: int
connections: dict[int, list[int]]
def dfs(now: int):
for _next in connections[now]:
dfs(_next)
if __name__ == "__main__":
dfs(INIT_NODE)
이해를 위해 핵심만 간략하게 표현: 이 코드는 이전에 방문한 정점을 다시 방문하게 되어 반복 과정이 종료되지 않는다.
깊이 우선 탐색의 탐색 방향성은 재귀 함수 내의 반복 과정에 크게 의존한다. 위의 경우에는 dfs 함수 내에서 connections[now]를 for문으로 불러오고 있다.
매 함수 호출 순간에 for문이 처음 _next에 할당한 값들이 모여, 깊이 우선 탐색 상에서 첫 번째 방향성을 설정한다. 예컨대 모든 connections[n]이 오름차순으로 정렬되어있다면, 깊이 우선 탐색은 각 반복 과정 상에서 가장 낮은 번호의 정점으로 탐색할 수 있는 끝까지 탐색한다.
너비 우선 탐색과 깊이 우선 탐색의 전체 구현과 예시
백준 온라인 저지 <1260번: DFS와 BFS> 문제를 예시로 너비 우선 탐색과 깊이 우선 탐색의 전체 내용을 구현한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
from collections import deque
def bfs(N: int, M: int, V: int, connects: list) -> list[int]:
# 1
result = []
# 2
visited = { each: False for each in connects }
q = deque()
q.append(V)
while q:
now = q.popleft()
# 3
if visited[now]:
continue
visited[now] = True
# 4
result.append(now)
for _next in connects[now]:
if visited[_next]:
continue
q.append(_next)
return result
이 문제는 탐색 방법에 따라 방문하는 정점의 순서를 출력하는 것이 목표이므로, 각 구현 부분에서 정점을 방문할 때의 번호를 기억한다. 코드 상의 #1과 #4가 이와 관련한 처리를 담당한다.
탐색 과정 중에 다른 처리를 도입하여야 한다면 대부분의 경우 #1, #4 부분에 추가적인 구현을 작성한다.
이전의 간략화된 구현과의 또 다른 차이점으로는 #2와 #3에서 방문한 정점에 대한 처리가 있다. 이 문제에서와 같이 각 정점 사이의 관계성이 방향 없는 간선에서는 특히 #2와 #3이 부재한다면 탐색이 무한히 반복하여 종료되지 않을 수 있다.
예를 들어, 1번 정점과 2번 정점이 서로 양방향 이동이 가능하다면, 대부분 구현에서 1번 정점과 2번 정점 사이를 중단 없이 무한히 순회한다.
따라서 #2에서 이미 처리한 정점은 참, 처리하지 않은 정점은 거짓의 값을 갖게 할 자료를 생성한 후, 실제로 #3에서 생성한 자료를 사용하여 정점의 중복 방문을 막는다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 1
visited = {}
result = []
def dfs_visit(now: int, connects: dict):
# 2
global visited, result
# 3
if visited[now] == True:
return
visited[now] = True
# 4
result.append(now)
for _next in connects[now]:
# 3
if visited[_next]:
continue
dfs_visit(_next, connects)
def dfs(N: int, M: int, V: int, connects: dict) -> list[int]:
# 2
global visited, result
visited = { each: False for each in connects }
dfs_visit(V, connects)
return result
깊이 우선 탐색은 재귀 함수를 이용하여 탐색을 진행하므로, 반복 과정을 재귀 함수로 정의하여서 탐색 진입점과 분리한다. 위에서는 dfs는 탐색 진입점, dfs_visit은 실제로 반복 과정 상에서 재귀적으로 호출하는 탐색 함수이다.
재귀적으로 구현한 깊이 우선 탐색은 #1, #2에서와 같이 전역 변수를 사용하는 구현을 많이 볼 수 있다. 이는 함수 사이에 주고받을 정보, 위 구현에서는 정점 방문 기록 visited, 결과로 반환할 값 result가 전역적으로 선언되었다.
1
2
3
4
5
6
7
def dfs_visit(now: int, connects: dict, visited: dict, result: list) -> Tuple[dict, list]:
...
for _next in connects[now]:
if visited[_next]:
continue
visited, result = dfs_visit(_next, connects)
이들 값은 반복 과정 시작 시에는 함수의 매개변수를 사용해, 반복 과정 종료 시에는 반환값을 사용해 전역 변수의 사용을 피할 수는 있다.
하지만 함수 호출 시에 인자를 주고받거나 지역변수를 갱신하는 구현이 추가되어야 하고, 상황에 따라서는 구현 과정에서 착오가 발생하여 이후에 잘못 구현된 부분을 찾는데 많은 힘을 쏟을 가능성이 높다.
1
2
3
4
5
6
7
// C++
typedef struct dfs_exchange {
vector<int> result;
hash_map<int, bool> visited;
} dfs_exchange_t;
dfs_exchange_t dfs_visit(int now, const hash_map<int, vector<int>>& connects, dfs_exchange_t& exchange);
파이썬과 같이 문법상 많은 부분에서 편리한 프로그래밍 언어가 아니라면 함수 간의 데이터 교환을 위해 조금 더 번거로운 구현을 추가해야할지도 모른다.
재귀적으로 구현한 깊이 우선 탐색을 클래스화하기
위와 같은 전역변수 사용과 함수 간 데이터 교환을 위한 추가 구현을 모두 피하는 방법으로 클래스 구현을 자주 사용한다. 개인적으로는 “전역 변수의 지역화”라는 표현으로 설명하는데, 재귀 함수를 클래스의 메서드로, 전역 변수를 클래스의 속성으로 구현하는 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
class DFS:
def __init__(self, N: int, M: int, V: int, connects: dict):
self.N = N
self.M = M
self.V = V
self.connects = connects
self.visited = { each: False for each in connects }
self.result = []
def __call__(self) -> list:
self._dfs_visit(self.V)
return self.result
def _dfs_visit(self, now: int):
if self.visited[now] == True:
return
self.visited[now] = True
# 4
self.result.append(now)
for _next in self.connects[now]:
# 3
if self.visited[_next]:
continue
self._dfs_visit(_next)
if __name__ == "__main__":
...
dfs = DFS(N, M, V, connects)
print(dfs())
이 경우에도 클래스 문법 상 요구되는 class ~~, self 키워드 등을 더 작성해야 하긴 하지만, 전역 변수 사용을 피하면서, 함수 간 데이터 교환을 위한 추가적인 구현을 피하는 데에 대한 대가로는 충분히 저렴한 단점이다.
간선과 간선 데이터 구조에 따른 처리
지금까지 검토한 내용에서 한 정점에 대해 연결된 다른 정점들을 찾는 데에는, 각 정점의 번호를 키, 해당 정점에 연결된 다른 정점 번호들을 값으로 갖는 connects: dict[int, list[int]] 값을 사용했다. 이 값은 인접 행렬(Adjacency Matrix)을 다소 변형한 데이터다.
1
2
3
4
5
6
{
0: [1, 3],
1: [0, 2],
2: [1, 3],
3: [1, 2]
}
지금까지는 무향 그래프만을 살펴보았다. 간선에 방향성이 지정되지 않았다는 의미에서 무향 그래프라고 한다.
모든 간선은 일방통행이 아닌 양방향으로 전이가 가능했다. 하지만 위의 데이터와 같이 유향 그래프, 일방통행 간선이 존재하는 그래프에 대해서도 대응 가능하다. 위 값에서는 0번 간선에서 3번 간선으로는 전이할 수 있으나, 3번 간선에서 0번 간선으로는 전이할 수 없다.
인접 행렬
인접 행렬은 $N$개 정점에 대해 $N \times N$ 크기의 정점 간의 연결 데이터를 담는 2차원 배열이다. 일반적으로 인접 행렬 adj에 대해서, adj[a][b]는 $a$번 정점에서 $b$번 정점으로 이동 가능한지를 기록한다.
역으로 adj[b][a]는 $b$번 정점에서 $a$번 정점으로의 이동이 가능한지를 기록한다. connects: dict[int, list[int]]와 마찬가지로, 인접 행렬 역시 유향 그래프에 대응할 수 있다.
| 0 | 1 | 2 | 3 | |
| 0 | true | false | true | |
| 1 | true | true | false | |
| 2 | false | true | true | |
| 3 | false | true | true |
이후에 더 복잡한 유형에서는 가중치가 부여된 간선이 등장하기도 한다. 간선의 길이, 통과 비용과 같은 값을 추가로 고려해야 하는 상황에서 비용을 가중치를 최적화하는 것이 목표인 상황이다. 그러한 상황에서는 BFS, DFS 외에도 더 좋은 해결책이 있지만, 인접 행렬은 여전히 유효하게 사용할 수 있다.
| 0 | 1 | 2 | 3 | |
| 0 | 2 | -1 | 1 | |
| 1 | 1 | 3 | -1 | |
| 2 | -1 | 1 | 1 | |
| 3 | -1 | 1 | 3 |
각 정점에 대해서 연결되어있는 다른 정점들에 대한 데이터만 갖는 connects: dict[int, list[int]]와 달리, 인접 행렬은 항상 $N \times N$ 크기의 배열을 생성한다. 일반적인 상황에서는 $N^2$의 고정 메모리 비용은 감내할만하다. 하지만 개인적인 취향으로는 상황에 따라서는 메모리 비용을 조금 더 줄일 여지가 있는 connects: dict[]의 구현을 선호한다.
Pro Tip: 정점 간 연결 여부만을 기록하는 인접 행렬은 connects: dict[]와 달리 바이너리 데이터형을 사용할 수 있으므로, 고정적으로 $N^2$의 메모리 부담이 있다고 하더라도 정수형 데이터를 다루는 connects: dict[]보다 메모리를 최적화할 수도 있다. 더 복잡한 구현이 필요할 수 있으나, 비트마스킹을 도입하면 최소 1바이트의 크기를 갖는 불리언 데이터를 1비트 크기로 더욱 축소할 수 있다.
격자 그래프
입력으로 주어지는 데이터의 구조에 따라서는, 인접 행렬을 새로 생성하는 것보다는 주어진 데이터 구조 내에서의 처리를 도모하는 것이 더 적절할 때도 있다.
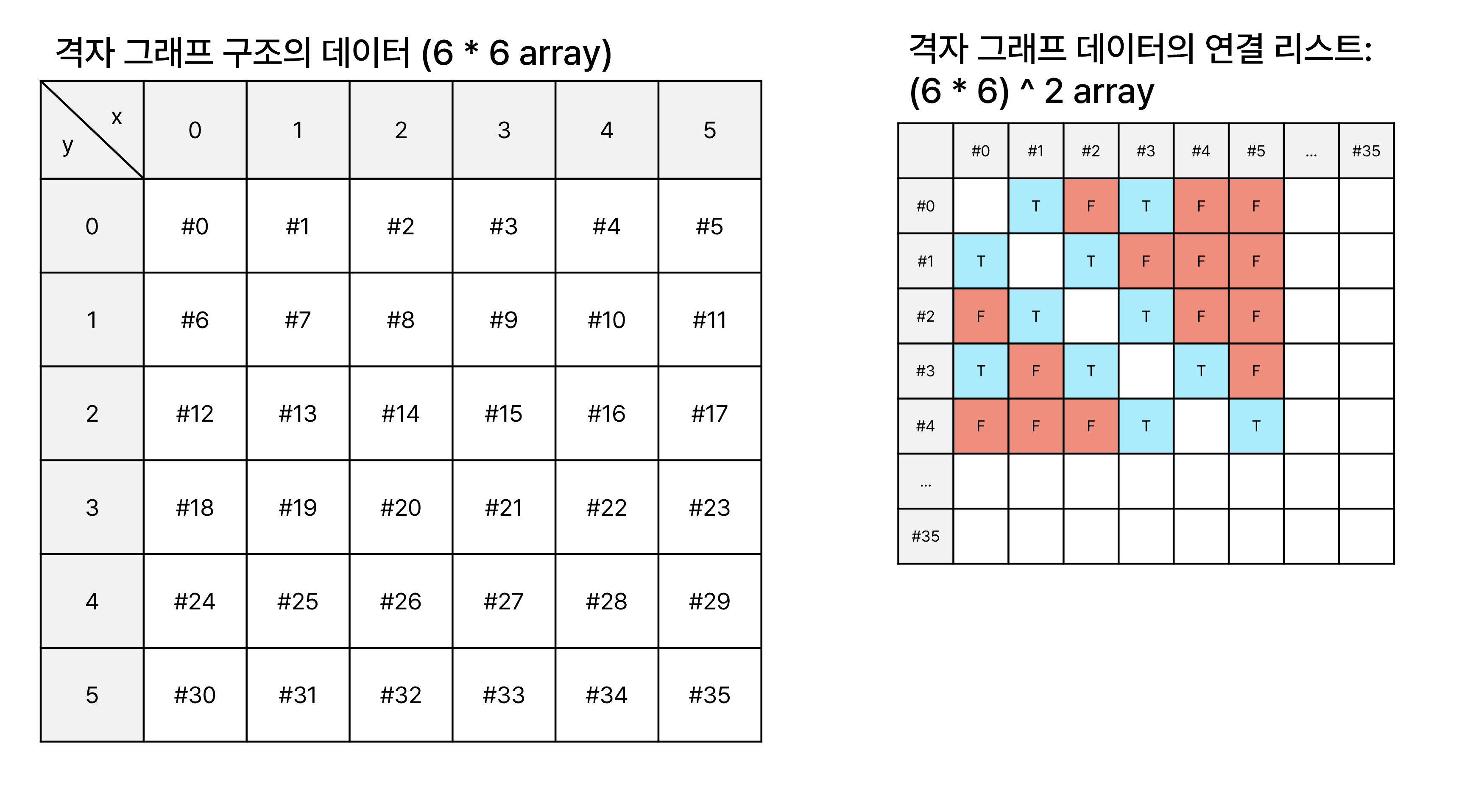
백준 온라인 저지 <7576번: 토마토> 문제는 격자 그래프가 입력으로 주어진다. $M \times N$ 크기의 격자 그래프는 $MN$개의 정점을 갖고 있다고 생각할 수 있다. $MN$개 정점에 대한 인접 행렬을 생성하면 $(MN)^2$의 메모리 비용이 발생한다.
이 문제 상에서 각 정점은 상하좌우로 인접한 네 칸에 대응해서 최대 네 개의 간선을 가질 수 있다. 개별 정점마다 $MN$의 메모리 공간에서 아무리 적어도 $MN-4$개의 데이터는 연결되지 않았다는 데이터를 가진다.
격자 그래프에서는, 주어진 데이터 그대로를 사용하는 것이 더 낫다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
q: deque
N: int
M: int
grid: list[list[int]]
while q:
y, x = q.popleft()
...
# 1
for dy, dx in ((-1, 0), (1, 0), (0, -1), (0, 1)):
ny, nx = y + dy, x + dx
# 2
if not (0 <= ny < N and 0 <= nx < M):
continue
# 3
if filtering_condition_about(grid[ny][nx]):
continue
q.append((ny, nx))
비단 BFS와 DFS뿐 아니라, 격자 그래프 데이터를 다루는 많은 처리에서는 위와 같이 구현하여 격자 그래프 상에서의 위치를 전이한다.
#1에서는 다음 상태로 전이할 수 있는 정점을 설정한다. 이 문제에서는 상하좌우를 확인하는 것이 목표이므로 $x$, $y$ 변화량 $\Delta x, \Delta y$을 for문으로 (-1, 0), (1, 0), (0, -1), (0, 1) 으로 순차 할당하였다. 만약 지뢰찾기 등 인접한 $3 \times 3$ 칸을 확인하고자 한다면, dy, dx에 대해 각각 반복 과정을 설정하여 이중 포문을 사용하는 것이 나을 수 있다.
1
2
3
4
5
for dy in (-1, 0, 1):
for dx in (-1, 0, 1):
if dy == 0 and dx == 0:
continue
ny, nx = y + dy, x + dx
#2에서는 다음 상태로 전이하는데 사용할 위치 정보 $x$, $y$가 범위 내에 있는지 확인한다. not 조건을 제거하여 continue를 사용하지 않고 조건 블록을 하나 더 추가할 수도 있지만, 개인적으로는 너무 깊은 코드 블록을 피하고자 하므로 continue를 사용하여 제어한다.
1
2
3
4
5
for dy, dx in ((-1, 0), (1, 0), (0, -1), (0, 1)):
ny, nx = y + dy, x + dx
if 0 <= ny < N and 0 <= nx < M:
# (content)
Pro Tip: 개인적으로는 유효하지 않은 범위를 조건으로 설정하는 것보다는 유효한 범위를 조건으로 설정하는 편이 가독성이 좋았다. $[0, N)$ 범위는 코드로도 표현하기 편하지만, $(-\infty, 0)$, $[N, \infty)$ 범위는 한 텀 생각할 시간이 더 필요했다.
1
2
3
4
# Condition Expression 1
0 <= ny and ny < N
# Condition Expression 2
not (ny < 0 or N <= ny)
#3에서 실제 문제 상황이 요구하는 제어 흐름을 작성한다. 토마토 문제에서는 익지 않은 토마토를 다음 반복 과정에서 익은 토마토로 전환하는 처리를 수행하도록 하므로 filtering_condition_about(grid[ny][nx])는 이미 익은 토마토(=1) 혹은 토마토가 들어있지 않은 칸(=-1)을 제외하는 처리가 될 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
while q:
y, x = q.popleft()
for dy, dx in [(-1, 0), (1, 0), (0, -1), (0, 1)]:
ny, nx = y + dy, x + dx
if not (0 <= ny < N and 0 <= nx < M):
continue
if field[ny][nx] == -1: # 벽
continue
if field[ny][nx] != 0: # 익은 토마토
continue
# field[i][j]에 대해 이중으로 의미 부여
# field[i][j] > 0: 토마토가 익었는지 여부
# field[i][j]: 토마토가 익은 시점
field[ny][nx] = field[y][x] + 1
q.append((ny, nx))
마무리
BFS와 DFS는 PS에서 쉬운 알고리즘 축에 속한다. 그래서 대부분 BFS, DFS는 다른 알고리즘에 비해 비교적 앞서 접하게 되는 느낌인 것 같다. 하지만 알고리즘이 낯선 입장에서는 이 역시 쉽지 않다. 파트 타임 강사 아르바이트를 하고 있는 학원의 알고리즘 반에서도, 많은 학생들이 이 단계에서 꽤 좌절을 겪는 편이다.
하지만 이후에 더 어려운 문제 상황에서는 BFS, DFS가 주 알고리즘이 아니라, 더 어려운 알고리즘으로 문제 상황을 처리한 후에, 데이터를 정리하면서 필요할 때마다 보조적으로 붙여쓰는 상황을 맞이하기 시작한다. BFS, DFS는 기본기가 된다.